Untangling information architecture and sitemaps

Don’t start a new website project without a defined purpose. Before any design file is created and before any line of code is written.
In this post, I’ll assume you’ve moved past this first, critical step. Soon thereafter you’ll move on to the Information Architecture of the site. Information Architecture defines the site structure and content hierarchy. Don’t confuse this with URL Structure. Will Critchlow from Distilled describes these concepts in this his Moz Whiteboard Friday video The Difference Between URL Structure and Information Architecture.
Discussions around Information Architecture are where “sitemap” often makes its first appearance.
What is a sitemap really?
As Will points out, URL Structure decisions can deviate from your Information Architecture. For example, your Information Architecture might imply that the webpage for red men’s shirts would live at https://www.example.com/men/shirts/red. But you may decide differently. In fact, that webpage might live at https://www.example.com/men-shirts-red for a number of reasons. Here’s the problem: sitemaps, in their true sense, are actually XML files that simply list a your site’s URLs. This is my own site’s sitemap.xml.
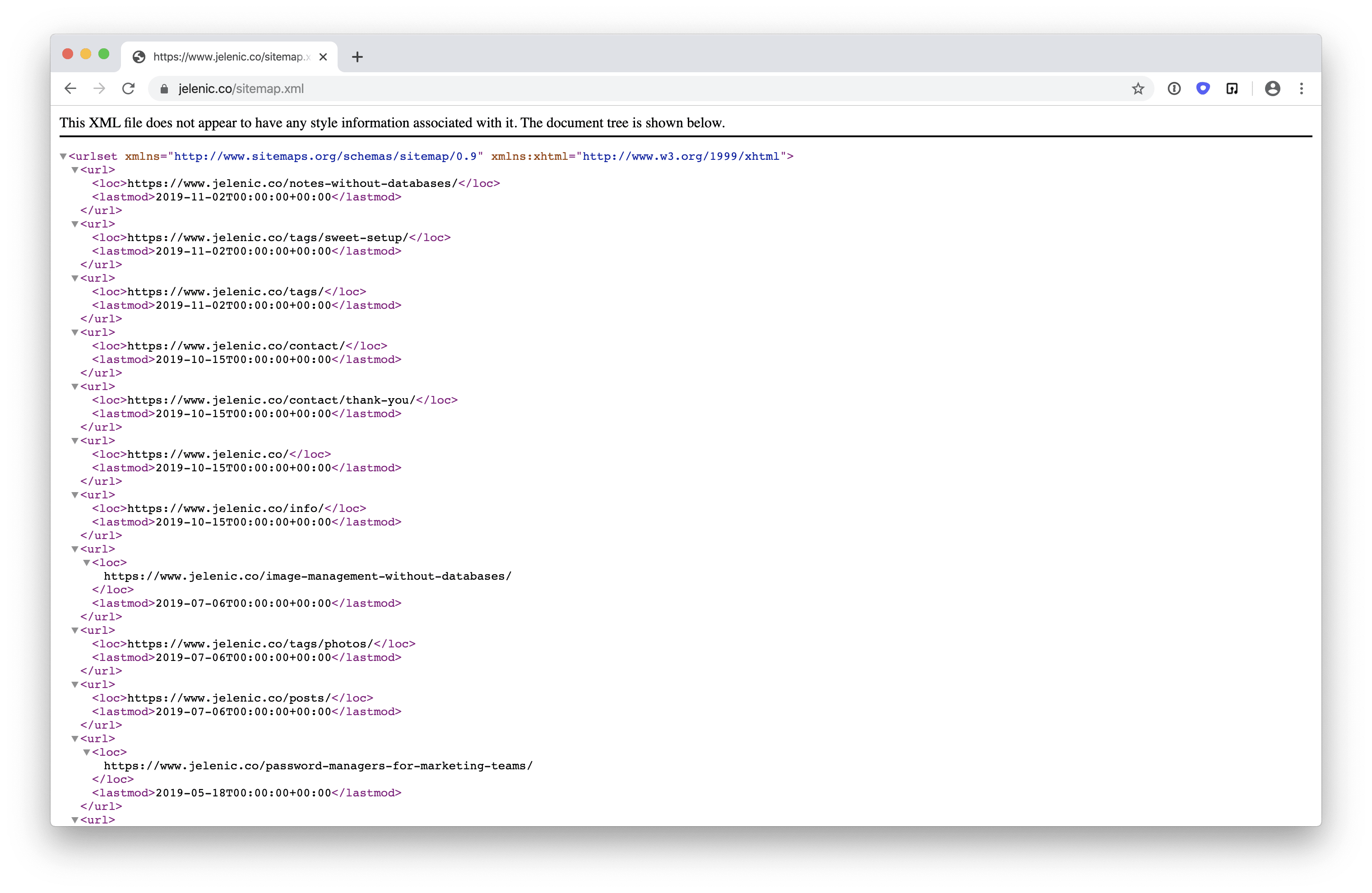
A sitemap can but needn’t actually contain the Information Architecture of the site. The only way it would actually contain the Information Architecture is if your URL Structure is rigidly coupled to your Information Architecture. That is, if your Information Architecture is encoded into your URL Structure. But this was Will’s entire point: they don’t need to be rigidly coupled and there are often good reasons to decouple them.
This is why you shouldn’t use the word “sitemap” to describe the visualization of Information Architecture.
Case in point
I’ll illustrate this with my own site, https://www.robertjelenic.com. Below is the Information Architecture of my site.
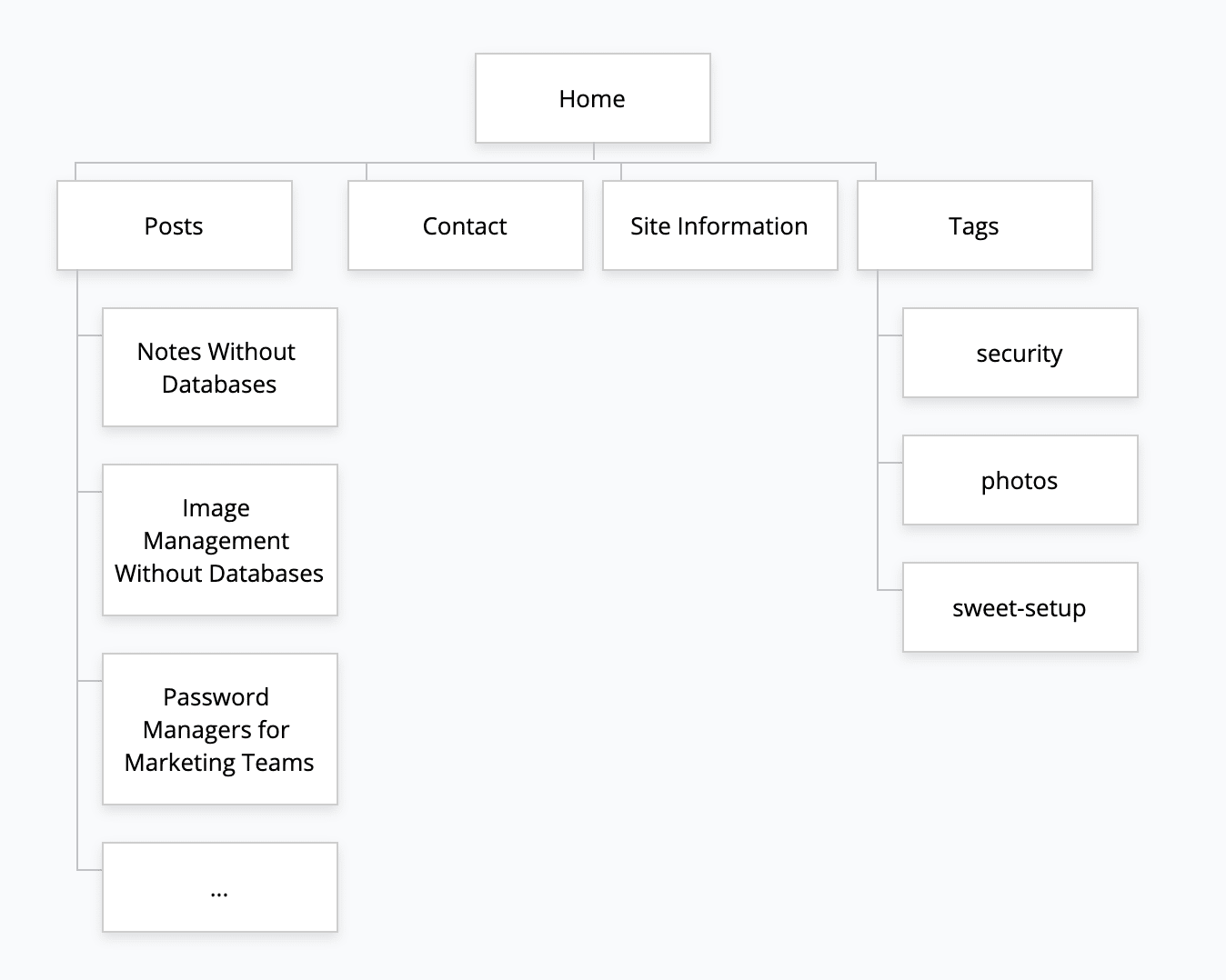
Pay special attention to the Posts “subfolder”. My posts are children of that subfolder. This also informs the site navigation: things like breadcrumbs, listing of children elements, global navigation and so on. But I won’t touch on navigation in this post.
Here’s where my URL Structure diverges from my Information Architecture: on the URL Structure, I decided to go with flat URLs for my posts, excluding the /posts/ in the URL. An example is my first post, Password Managers for Marketing Teams (https://www.robertjelenic.com/password-managers-for-marketing-teams).
Now let’s see how a sitemap visualization tool displays my site’s structure. Dynomapper ingests a site’s sitemap.xml file and visualizes it.

Notice that my posts don’t get organized into a Posts subfolder. Their URLs don’t contain any reference to it. Dynomapper didn’t “miss” anything; it worked properly and has no real way of knowing the true Information Architecture (of course, it can explore that by crawling the pages via the navigation but we won’t go there for now). Dynomapper just visualizes what it finds at the root sitemap.xml.
Also note that the three existing tags, security, photos and sweet-setup, were organized into the Tags subfolder based on their URLs
https://www.robertjelenic.com/tags/securityhttps://www.robertjelenic.com/tags/photoshttps://www.robertjelenic.com/tags/sweet-setup
These page URLs happen to reflect the Information Architecture, but they could just as easily not have done so if I had chosen different URLs.
Closing thoughts
This is a very small example but you can imagine how this gets more confusing as the structure of your site grows.
Next time you’re laying out a site, call Information Architecture what it is. Then decide your URL structure. The sitemap follows from those decisions. I’ve found getting this nomenclature straight can avoid confusion down the road.